1. 통합 (Integration)
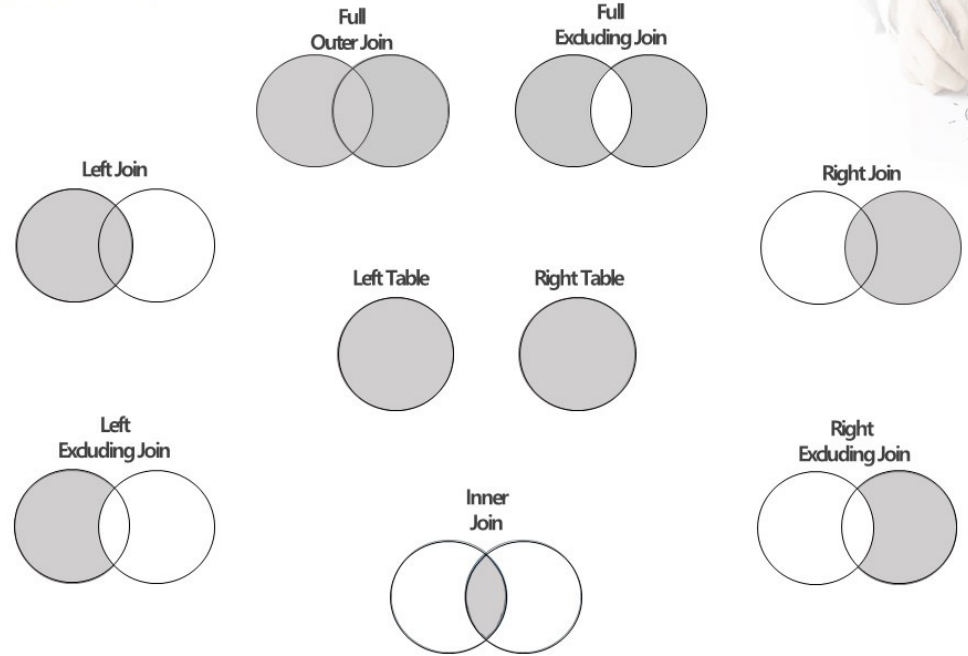
통합(Integration)의 개념에는 결합이 있다. 조인 혹은 결합은 두 개의 데이터를 하나로 합치는 것이다. 데이터베이스 용어로 얘기하면 관계형 DB에서는 모든 자료가 테이블에 들어있다. 테이블은 단순히 표이다. 조인은 두 개의 표를 하나로 합치는 것인데, 일반적으로는 두 개를 합칠 때 겹치는 부분이 있어야 하며, 이것은 기본적으로 똑같은 칼럼을 얘기한다.
기본적으로 왼쪽 테이블, 오른쪽 테이블이 있을때 어느 테이블을 기준으로 합치는 것에 따라 Left Join은 왼쪽 테이블을 기준으로 하여 왼쪽 테이블은 다 들어가고, Right Join은 오른쪽 테이블을 기준으로 하여 오른쪽 테이블이 다 들어간다. Full Excluding Join은 교집합만 빼고 다 들어가는 것이고, 중복되는 개념을 가지고 조인을 하는 것이 Inner Join이고, Full Outer는 합집합, Excluding Join은 교집합은 빠지는 개념이다.
2. 축소 (Reduction)
데이터 축소에서 Filtering이라는 개념은 걸러내겠다는 것이고 Sampling은 데이터의 양이 너무 많아 분석의 어려움이 있거나 시간 관점에서 현실적이지 않을 때 분석에 적정하게 조절하는 것이다. 차원 축소라는 말이 있는데 데이타의 Feature 개수를 줄이는 것이다.
데이터의 차원이 늘어날수록 해당 공간의 크기가 기하급수적으로 증가하고 데이터의 밀도는 희박해지기 때문에 데이터 분석에 필요한 데이타의 수는 기하급수적으로 증가하게 되어 분석시간이 오래 걸리고 계산복잡도가 증가한다. 이를 차원의 저주 (Curse of Dimensionality)라 한다.

3. 샘플링 (Sampliing)
Sampling을 한다고 했을때 전수조사 vs. 표본조사가 있다. 전수조사는 모집단의 모든 구성원을 대상으로 조사하는 것으로, 인구센서스가 있으며 비용과 시간이 많이 드는 단점이 있다. 표본조사는 대상 전체를 조사하는 대신 일부를 조사한다. 전수조사가 어려운 예로는 파괴실험 (자동차 충격테스트, 타이어 수명테스트), 대통령 후보 지지도 조사, 농축산물 품질검증 등이 있다.
일반적으로는 표본조사를 하게 되는데 표본의 요건은 모집단을 대표할 수 있어야 한다. 샘플을 가지고 왔는데 예외적인 것만 가지고 왔으면 이것이 모집단을 대표한다고 할 수 없다. 표본의 크기가 클수록, 모집단에서 골고루 추출될수록 표본의 대표성은 커진다. 무작위로 추출하는 것은 바로 이런 편향성을 배제하기 위한 것이다.
연구결과를 왜곡시키는 오차는 다음과 같다.
- 표본오차(Sampling error)
- 모집단을 모두 조사하지 않고 일부의 표본만을 조사하기 때문에 발생하는 오차
- 표본크기가 커질수록 작아지며, 전수조사시 0이 됨
- 조사에서 사용한 표본이 모집단의 특성을 그대로 갖기 어렵기 때문 - 비표본오차(non-sampling error) -> 전수조사로도 이것을 줄이기 쉽지 않음
- 무응답오차: 응답을 거부하는 경우 발생되는 오차
- 응답오차
. 조사자 오차: 조사자 표본 잘못 선정, 데이터 잘못 분석
. 면접자 오차: 능력없는 면접자, 면접자의 실수나 태만
. 응답자 오차: 응답자의 실수나 무성의한 답변
샘플링을 하는데 여러가지 방법이 있다. 각 방법을 정리하면 다음과 같다.
- 단순임의추출 (Simple Random Sampling)
- 전체에 대해 무작위 추출
- 난수표(random number table)를 이용하여 표본의 크기만큼 개체를 선택

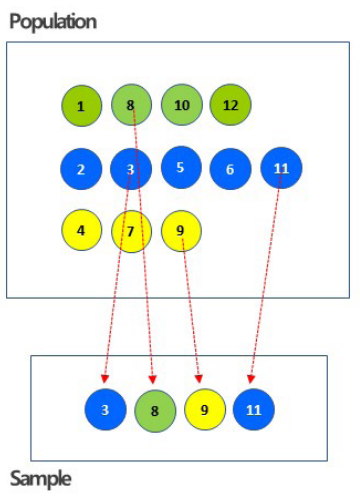
- 층화추출 (Straightified Random Sampling)
- 데이터 내에서 지정한 그룹별로 지정한 비율만큼의 데이터를 임의로 선택
- 모집단의 각 층의 비율만큼 추출함
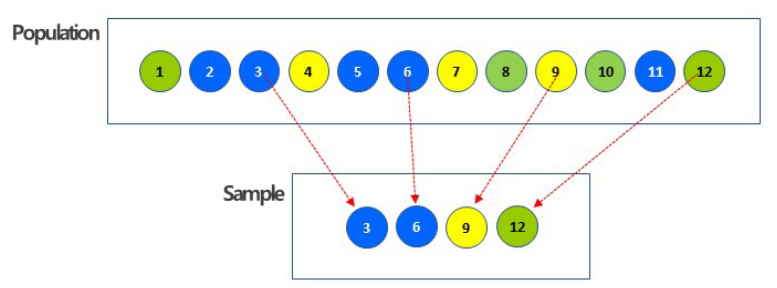
- 계통추출 (Systematic Sampling)
- 첫번째 요소는 무작위로 선정, 목록의 매 k 번째 요소를 표본으로 선정하는 표집 방법
- 모집단의 크기를 원하는 표본의 크기로 나누어 k를 계산 (k는 표집간격, sampling interval)
- 만약 요소들의 목록이 표본이 추출되기 전에 무작위로 되어 있다면, 그 목록에서 계통 추출법을 통해
추출된 표본은 실제로는 단순임의 표본과 같다고 할 수 있음
- 만약 표본이 추출되기 전 요소들의 목록이 무작위로 되어 있지 않고 주기성(periodicity)을 띄고 있다면, 계통 추출법을 통해 추출된 표본은 매우 어긋난 표본이 될 수 있으며, 모집단을 전혀 반영하지 못하게 됨
- 군집추출, 집락추출 (Clustering Sampling)
- 소집단 자체를 표본대상으로 하기 때문에 각 소집단이 가능한 한 모집단을 대표할 수 있는 소규모의 집단이 되어야 함 가장 이상적
- 군집간 동질성, 군집 내 이질성인 경우 사용
- 장점
. 군집을 잘 규정하면 비용이 절감
. 군집의 특성을 평가하고 모집단의 특성과 비교할 수 있음
- 단점
. 단순임의추출법 보다 군집을 과대 또는 과소 평가해서 표본오차를 계산하기가 어려울 수 있음
(예) 백화점 지점별 큰 차이가 없다면, 어느 한 지점을 선택하여 그곳 고객들을 대상으로 전체/표본 추출하여 데이터 분석이 가능

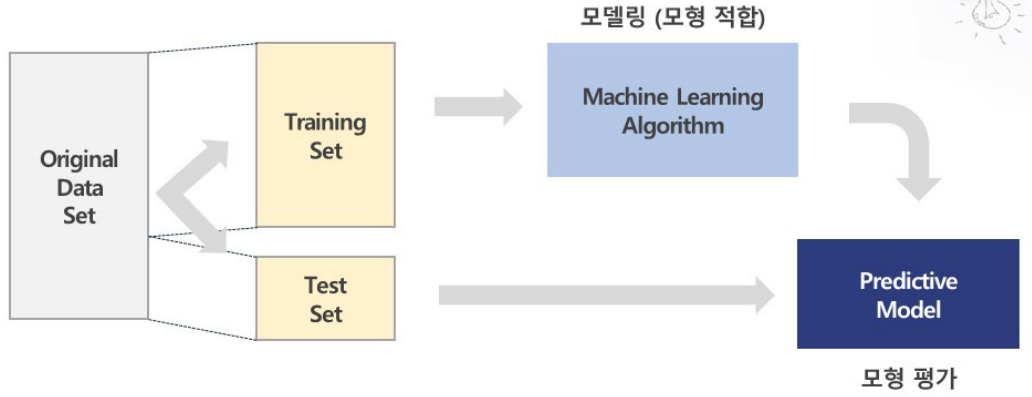
샘플링하는 방법중에 Training-Test Data Split 개념이 있다. Split은 데이터를 쪼개는 것인데, Original Data set 이 있으면 이 데이터를 가지고 모델을 만들 때는 train과 test 데이터로 분리한다. 비율은 대체로 9:1 ~ 7:3이다. 일반적으로 train 데이터를 좀 더 많이 쓰고 이 데이터를 가지고 모델을 만든다. 만든 모델을 가지고 성능평가를 할 때 test 데이터를 사용한다. 회귀분석의 경우 오차를 줄이는 방향으로 모델을 평가할 것이고, 분류의 경우의 경우 Yes/No를 얼마나 잘 맞추는지 평가한다.
'데이터사이언스 > 전처리' 카테고리의 다른 글
| 데이터 전처리_변환 (Transformation) (0) | 2023.04.26 |
|---|---|
| 데이터 전처리_데이터 클리닝 (Data Cleaning) (0) | 2023.04.24 |


댓글