머신러닝은 데이터를 기반으로 예측, 추론, 분류, 학습을 하는데 사용하는 언어나 툴에 맞게 바꾸어야 한다. 우리가 수집한 원시 데이터가 사용할 프로그램, 툴에 딱 맞게 들어오면 좋겠지만 현실은 그렇지 않다. 데이터 분석가는 내가 사용하는 알고리즘 툴 언어에 맞게 데이터를 바꾸어주어야 한다.
데이터 전처리(Data Preprocessing)는 데이터 분석작업 전에 데이터를 분석하기 좋은 형태로 만드는 과정을 총징하는 개념이다. 실제 데이터 전처리에 많은 비용과 시간이 소요된다. 전처리를 어떻게 하느냐에 따라 성능은 많이 차이가 날 수 있다. 데이터의 품질은 분석결과의 출발점이 된다. 오리지널 데이터를 데이터 클리닝, 즉, 통합, 선택을 통해 분석할 수 있는 타깃 데이터를 만들어 놓고 이 데이터는 전처리를 거쳐서 모델을 만들게 된다. 모델을 통해 패턴을 찾고 원하는 결괏값들이 나오게 되면 새롭게 지식을 만들게 된다. 이 과정들이 이어질 때 중요한 파트가 데이터 전처리이다.

산업분야에서 데이터 전처리는 순환적으로 돌게 되는데, 데이터를 준비할때 필요한 데이터를 고르고 난 후 데이터를 정제시켜야 한다. 알고리즘에 맞게 형태를 바꾸거나 문자형, 수치형, 구간화, 표준화 등을 써서, 사용하는 툴, 알고리즘에 맞춰 바꾸는 작업을 통해 데이터를 준비하게 된다.

데이터의 품질이 높은 경우에도 전처리는 필요하다. 구조적 형태가 분석 목적에 적합하지 않은 경우, 즉, 형태가 안 맞을 경우 바꾸어야 한다. 사용하는 툴, 기법에서 요구하는 데이터 형태일 경우와 데이터가 너무 많을 경우 데이터가 모두 안 들어가기 때문에 골라야 한다. 이러한 모든 경우 데이터 전처리를 해야 한다.

데이터 품질을 낮추는 주요 원인들이 있다. 첫째는 불완전(Incomplete), 데이터의 필드가 비어있는 경우, missing value 또는 한 줄이 통채로 비어 있는 경우 missing value라고 하는데 이것이 불완전이다. 둘째는 잡음 (Noise), 데이터에 오류가 포함된 경우, 이상치(outlier) 같은 경우가 여기에 포함된다. 셋째는 모순 (Inconsistence), 데이터 간 정합성, 일관성이 결여되어 있는 경우이다. 분명히 타입에 나이라고 되어 있으면 숫자가 나와야 하는데 갑자기 문자로 나와 있는 경우, 또는 학점을 구간화 시켰는데, 갑자기 E학점이 들어와 있는 경우이다.
데이터 전처리의 주요 기법은 다음과 같다.
- 데이터를 정제 (Cleaning) 시키고
- 정제된 데이터를 하나로 통합 (Integration) 시키고
- 의미있는 데이터만 뽑아서 축소 (Reduction) 시키고
- 모델에 맞춰 변환 (Transformation) 하는 것이 있다.

데이터 정제에서 결측값(missing value)은 존재하지 않고 비어있는 상태, DB에서 NULL 값인 경우를 말하여 후속 분석 결과에 영향이 최소화되도록 데이터를 채운다. 결측값에 대한 처리 방법은 다음과 같다.
- 수작업으로 채워 넣음
- 특정값 사용 (똑같은 값으로 채운다. 많이 사용되지는 않는다)
- 평균값 사용 (전체 평균 혹은 기준 속성 평균)
- 가장 가능성이 높은 값 사용 (회귀분석, 보간법 등 가장 많이 사용한다.)
- 해당 데이터 행을 모두 제거 (가지고 있는 데이터가 충분할 경우)
이상값(Outlier)은 대표적인 잡은 요소이며 이상값으로 판단되는 값에 의해 경향성 훼손이 발생한다. 아주 드물게 나타나는 특이 값, 오류 (값 오류, 샘플링 오류)로 보기도 한다. 아주 다양한 Outlier 탐지기법이 존재하는데, Box Plot 또는 Histogram, Scatter chart 등 시각화 도구를 활용할 수 있다.

떨어져 있는 데이터, 항상 이상값 이상치일까? 떨어져 있기는 한데 데이터가 여러 개 있을 경우 새로운 그룹이 만들어진 건가라고 의심해 볼 필요가 있다. 그래서 2개의 그룹으로 쪼개져 있을 수도 있기 때문이다. 떨어져 있는 데이터가 몇 개 인지도 볼 필요가 있다. 이것은 밀도를 가지고 얘기하기도 한다.

이상값 탐지 방법으로는 다음이 있을 수 있다.
- 수치형으로 탐지방법
- IQR 기준, Box Plot를 쓰는 방법 - 확률이나 분포를 이용하는 방법
- Variance: 정규분포에서 97.5% 또는 2.5% 이하에 위치한 값 (z-score)
- Likelibood: 베이즈 정리에 의해 데이터세트가 가지는 정상/이상 샘플에 대한 발생확률로 판단. 머신러닝 파트에서는 조건부 확률을 Likelihood(우도)라고 한다. 조건부 확률을 가지고 전체에서 정상일 확률, 전체에서 이상을 확률로 볼 수 있다. - 머신러닝 기법을 활용하는 방법
- Nearest-neighbor: 모든 데이터 쌍의 거리를 계산하여 검출
- Density: 밀도가 있으면서 데이터 세트로 부터 먼 데이터는 이상치가 아니라 그룹으로 볼 수 있다.
- Clustering
IQR 기반의 이상값 탐지기법은 Boxplot을 기반으로 하며 그 방법은 다음과 같다.
- IQR: Inter Quantile Range (3사분위수-1사분위수)
- Tukey 방법 : 기준은 Q1과 Q3
- 상한: Q3 + 1.5*IQR
- 하한: Q1 - 1.5*IQR - Carling 방법: 기준은 Median
- 상한: M + 2.3*IQR
- 하한: M - 2.3*IQR

LOF (Local Outlier Factor)는 밀도까지 보는 개념 (거리 + 밀도)이다.
- 다차원 데이터의 아웃라이어 제거에 효과적인 방법
- 관측치의 비정상적인 정도를 반영하는 점수를 계산 (로컬 아웃라이어 계수)
- 주어진 데이터 포인트의 이웃에 대한 로컬 밀도 편차를 측정한 후 이웃들보다 밀도가 훨씬 낮은 샘플을 감지
- 정상 데이터는 이웃과 유사한 로컬 밀도를 가지고 비정상적인 데이터는 훨씬 더 낮은 국소 밀도를 가질 것으로 예상
- 로컬 및 전역속성을 모두 거려하는 점이 특징
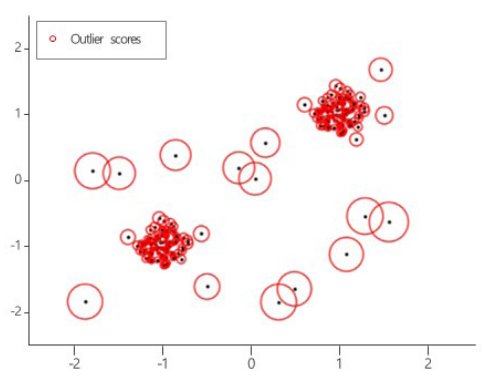
기타 잡음 요소는 다음과 같다.
- 개체의 식별 (동일한 데이터가 다른 이유로 존재할 때 어떻게 동일한 데이타임을 알 수 있을까?)
- 중복
- 중복 데이터는 제거해야 하고, 중복인가 아닌가를 판단하는 룰이 있어야 한다.
- 유도 속성과 이에 의한 오류 (예) 월소득/년소득, 생년월일/나이
- 중복 데이터 제거 방법은 DB의 정규화 vs. 비정규화로 중복을 제거한다.
- 상관분석으로 두 변수 간의 연관성이 있는지, 절대값 1에 가까울수록 강한 선형관계가 있으므로 중복인지 아닌지 확인할 필요가 있다.
- 동일 데이터에 대한 속성값 차이
- 표현, 척도, 부호 등의 차이
- 데이터 레벨의 차이: 나이의 30과 통장 잔고의 30원 차이는 전처리 단계에서 가중치 값을 조절하면서 정리해야 한다.
- 중복
잡음처리는 다음과 같다.
- 구간화(Binning 또는 Bucketization) : 데이터 값을 구간화하고 각 구간의 평균값, 중앙값, 경계값 등등을 구간값으로 사용하여 평활화하는 방법
- 회귀(Regression) : 회귀함수에 의해 데이터를 평활화하는 방법
- 군집화(Clustering) : 유사한 값끼리 그룹화하여 군집의 센터값을 사용하는 방법
'데이터사이언스 > 전처리' 카테고리의 다른 글
| 데이터 전처리_변환 (Transformation) (0) | 2023.04.26 |
|---|---|
| 데이터 전처리_통합 (Integration) 및 축소 (Reduction) (0) | 2023.04.25 |


댓글