1. 머신러닝이란?
머신러닝(Machine Learning, 기계학습)이란 컴퓨터 프로그램의 데이터 처리 경험을 바탕으로 정보처리능력을 향상시키는 것, 혹은 이와 관련한 학문이다라고 정보통신용어 사전에 정의되어 있다. 자율주행자동차, 필기인식 등 알고리즘 개발이 어려운 분야에 적용이 가능하다.

머신러닝은 어느 시기에 누가 정의하느냐에 따라 다양한 정의가 있다. 아서 사무엘(Arthur Samuel, 1901~1990)은 이미 1959년에 머신러닝의 용어를 대중화시켰다. 실제로 알파고 나오기 이전부터 하나의 학문으로 존재했던 개념이다. 알파고가 몇 년 전에 이세돌 프로를 이겼을 때 실제로 바둑은 경우의 수가 굉장히 크기 때문에 대부분의 머신러닝 학자들은 아직은 사람 못 이기지 않나 생각했다. 경우의 수가 너무 많기 때문에 돼? 그랬는데 이겼다. 아래 그림이 체스인데 바둑의 경우의 수보다 작다. 1990년대 IBM 딥블루가 전세계 체스챔피언을 이겼다. 처음에는 컴퓨터가 이기고 채스챔피언이 이기고, 최종 승부에서 컴퓨터가 완전히 이겼다. 그다음부터 체스는 끝. 그리고 바둑으로 넘어왔다. 아서 사무엘이 기본적인 이론을 만들었다.
위키피디아에서는 경험을 통하여 자동으로 계산되는 컴퓨터 알고리즘에 대한 학문으로 머신러닝을 정의한다. 요즘 딥러닝이 많이 유명해지면서 머신러닝과 헷갈려한다. 큰 그림을 그려보면 인공지능이 가장 큰 개념이고 그 안에 머신러닝, 패턴인식 등 여러 가지 분야가 있고, 그다음에 머신러닝 안에 여러 가지 알고리즘이 있는데, 그 시대를 풍미하는 알고리즘이 있는데 현재 가장 유명한 알고리즘이 딥러닝이라는 알고리즘이다. 인공지능 > 머신러닝 > 딥러닝으로 정리할 수 있다.
머신러닝과 전통적인 프로그래밍의 차이가 뭐냐? 전통적인 방법은 "Write rules", 즉 개발자가 직접 코딩을 한다는 것이고, 머신러닝은 데이터를 보고 머신러닝 알고리즘이 학습을 하여 성능을 높인다. 여기에 자동화 개념이 들어가 있다.
자동화되어 있다는 것이 전통적인 프로그래밍의 차이이다.
머신러닝과 데이터마이닝과의 차이는 크게 두지 않는다. 두 개는 관점의 차이가 있을 뿐이다.
2. 머신러닝의 종류
머신러닝 알고리즘의 종류는 다음과 같이 정리할 수 있다.
그중 가장 기본이 되는 3가지 종류의 머신러닝 알고리즘이 Supervised, Unsupervised, Reinforcement이다.
Supervised Learning (지도학습, 교사학습, 감독학습)은 학교에서 시험을 보고 채점을 하는데 채점은 교사가 한다. 문제는 채점을 하기 위해서는 정답지가 있어야 하는데, 우리가 기본적으로 모델에 사용데이터가 있는데 Target value도 가지고 있다. Class, Label, 혹은 출력값 같은 말이다. 정답이 있다는 얘기이다. 실제로 거의 대다수의 알고리즘이 Supervised 알고리즘이다. 딥러닝 알고리즘도 Supervised 알고리즘이다. 실세로 supervised 알고리즘이 성능이 가장 좋다. 정답지가 있기 때문에 정답을 맞혀가려 할 것이고, 오차를 줄여가려고 할 것이다. 출력값이 결과, 혹은 종속변수, Target value가 수치형이 나왔다면 이 알고리즘은 회귀다. 만약에 출력값이 범주형 데이터일 경우, 쉽게 문자 텍스트 일경우 대부분 이 문제는 분류문제를 푸는 것이다.
Unsupervised Learning (비지도학습, 자율학습)은 우리가 가지고 있는 데이터 셋 안에 target value, 출력값이 없다. 일반적으로 타깃이 없을 때, 즉 정답이 없을 때 가장 많이 쓰는 방법이 비슷한 아이를 묶거나 차원을 축소하는 방식을 쓴다.
Reinforcement Learning (강화학습)는 어떤 구체적인 행동에 대한 지시가 없이 목표만 주어진다. 그러면 목표달성을 위해서 보상(reward)을 가장 많이 주는 방식을 스스로 찾아간다. 학습한 내용에 최고의 결과를 얻기 위해 전략으로 활용되는데 일반적으로 사람이 학습하는 방법과 똑같다고 합니다.
그 밖의 알고리즘 중에 Semi-supervised 가 있는데, 모든 데이터에 label을 달아줄 수 없는 현실을 반영한 알고리즘이다. Label이 붙은 것과 안 붙은 데이터를 동시에 사용한다. Unsupervised 알고리즘이 군집을 만들고 4개의 군집일 때 가장 높은 성능이 나왔을 때 이 결과를 놓고 다시 Supervised 러닝처럼 그 군집에 대해 Target 값을 주고 러닝 알고리즘을 돌리는 기법이다.
그리고 Transfer 러닝이라는 개념이 있는데 기존에 학습된 모델을 가지고 있고, 우리가 해결하려는 문제가 비슷하나, 학습데이터가 부족할 때 사용한다. 데이터가 부족하면 모델 만드는 것이 힘들기 때문에 기존에 풍부한 데이터를 가지고 만든 모델을 가지고 와서 쓰는 것이다. 기존에 만들어진 모델을 조금 미세조정하거나 파라미터 값을 조정해서 결과를 보는 방법이다.
3. 머신러닝 워크플로우 (Machine Learning Workflow)
일반적으로 머신러닝은 다음의 단계를 거치게 된다.
- Collect data. 유용한 데이터를 최대한 많이 확보하고 하나의 데이터 세트로 통합
- Prepare data. 결측값, 이상값, 기타 데이터 문제를 적절하게 처리하여 사용가능한 상태로 준비
- Split data. 데이터 세트를 학습용과 평가용 세트로 분리
- Train a model. 이력 데이터의 일부를 활용하여 알고리즘이 데이터 내의 패턴을 잘 찾아주는지 확인
- Test and validate a model. 학습 후 모델의 성능을 평가용 데이터 세트로 확인하여 예측 성능을 파악
- Deploy a model. 모델을 의사결정 시스템에 탑재 / 적용
- Iterate. 새로운 데이터를 확보하고 점증적으로 모델을 개선
그 단계 중 4가지 단계, 즉 데이터를 준비하고, 데이터를 분리하고, 모델을 만들고, 모델을 평가하는 4가지 단계에 중점을 둔다.

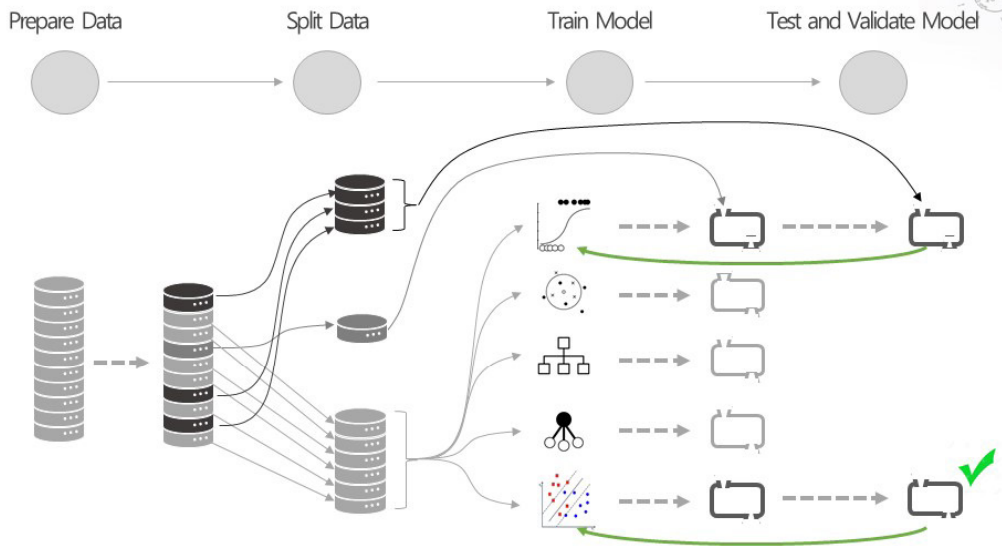
머신러닝에서는 알고리즘을 잘 이해하고 있어야 한다. 알고리즘을 모르면 전처리를 못한다. 전처리는 알고리즘에 종속적이다. 어떤 알고리즘을 쓰느냐에 따라 전처리 방식이 달라진다. 대부분 알고리즘을 사전에 선택한 경우 데이타를 준비하고 데이타를 분리하고 모델을 만들고 그 결과를 평가한다. 우리가 가지고 있는 데이터가 어떤 모델이 성능이 잘 나오게 만들어 주는지는 신만이 알고 있다는 말이 있다. 그 얘기는 우리가 아는 최고의 방법은 여러 가지 알고리즘을 다 돌려본 다음에 가장 좋은 성능을 가진 알고리즘을 선택한다. 여러 개의 모델을 만들기 위해서는 전처리를 여러 번 해야 하기도 한다.
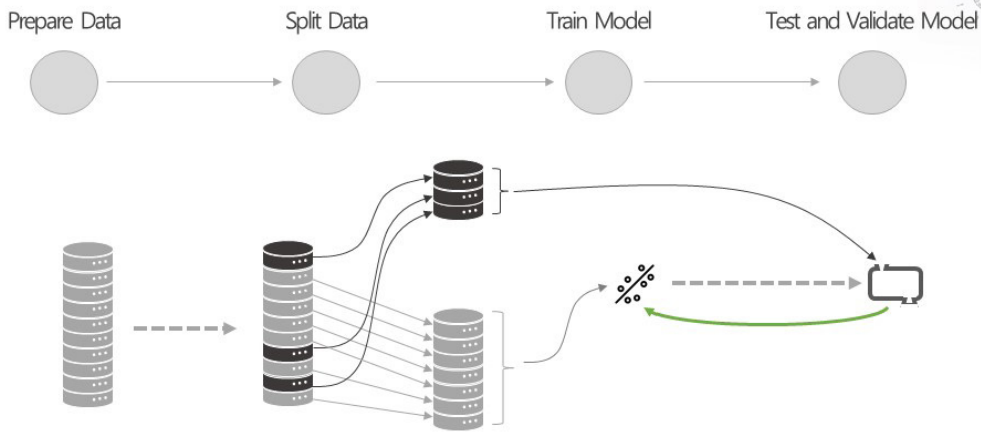
여러 알고리즘 가운데 선택하는 경우 데이터에 대해서 알고리즘별로 다 다르기 때문에 여러 가지 알고리즘을 써서 결과가 나오면 가장 좋은 알고리즘을 선택하여 사용하는 것이 일반적인 워크플로우이다.
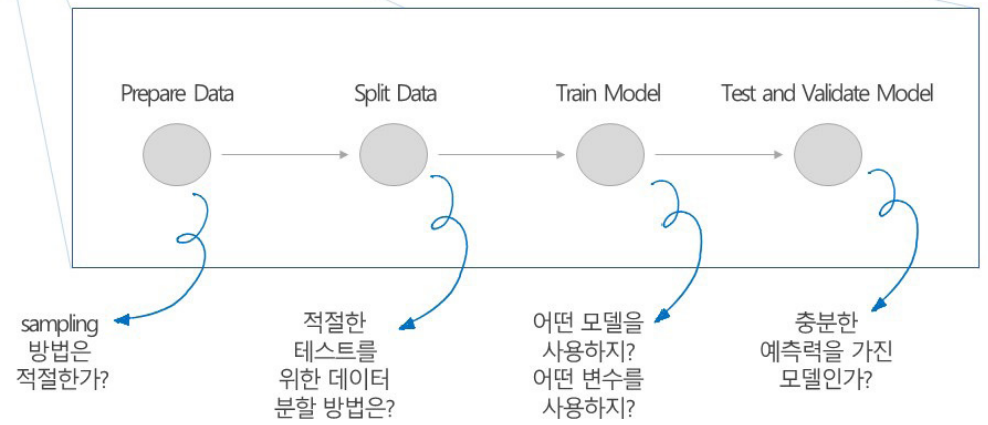
4가지 관심 있는 주제는 데이터를 준비할 때 샘플링 방법은 적절한가? 그 데이터를 분할하는 적절한 방법은? 모델을 평가할 때 모델을 어떻게 만들고 어떤 모델을 만들고 어떤 변수를 사용할 것인지? 그다음에 결과가 나오면 테스트 데이터로 평가하게 되는데 먼저 validation을 먼저 할 수도 있지만 테스트된 결과를 모델의 성능을 가지고 충분히 잘 예측하는지? 원하는 데로 잘 분류하는지? 성능을 평가하게 된다. 여러 개를 돌려보고 가장 좋은 것을 선택하게 된다.
'데이터사이언스 > 머신러닝' 카테고리의 다른 글
| 의사결정나무 (Decision Tree) (2) | 2023.04.22 |
|---|---|
| 특성공학 (Feature Engineering) 모델평가기법 (0) | 2023.04.21 |
| 특성공학 (Feature Engineering) 언더피팅 / 오버피팅 (0) | 2023.04.20 |
| 나이브 베이즈 (Naive Bayes) (1) | 2023.04.19 |
| KNN (K-Nearest Neighbors) 알고리즘 (0) | 2023.04.16 |




댓글